Human activity recognition (HAR) has numerous applications, including real-time task assistance, automated exercise tracking, rehabilitation, and personal informatics. Over the years, researchers have explored numerous modalities to sense a user’s actions, and sound has proven to be a useful signal. Sounds resulting from physical activities, such as washing one’s hands or brushing one’s teeth, are often distinctive and enable accurate HAR. However, sampling audio at rates between 8 and 16 kHz carries a power consumption and compute cost. Moreover, these audio ranges capture human speech content and other sensitive information that users might not want to have recorded.
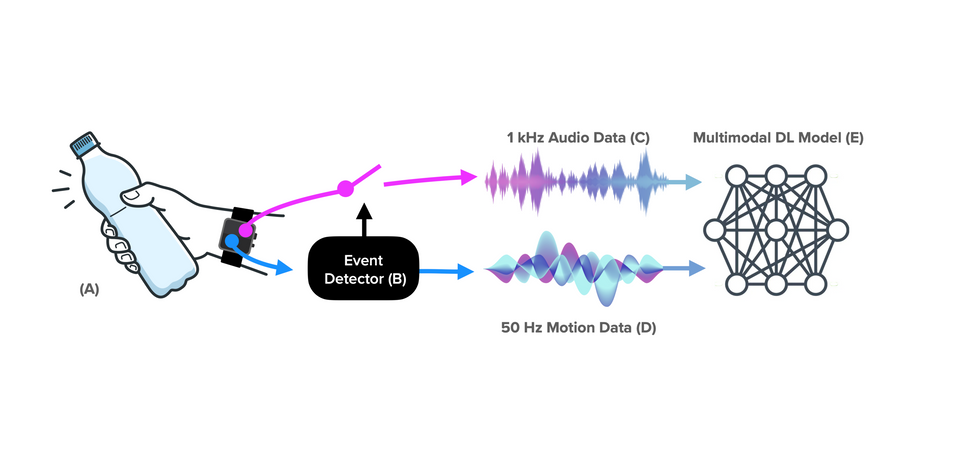
In a bid to protect user privacy, researchers have proposed to featurize recorded data. If done at the edge, featurization is considered privacy-sensitive, but it comes with considerable processing cost. Furthermore, an always-on acoustic activity recognition system increases the power burden; especially on resource-constrained devices such as smartwatches, where the battery cannot be made much larger. In response, we present SAMoSA - Sensing Activities with Motion and Subsampled Audio. Our approach first uses power- and compute-optimized IMUs sampled at 50 Hz to act as a trigger for detecting the start of activities of interest. IMUs are ubiquitous, are heavily engineered for efficiency, and numerous prior works have shown the effectiveness of IMU data to detect user activities. Once we detect the start of an activity using an IMU, we use a multimodal model that combines motion and audio data for classifying the activity. To further minimize the computation cost of processing audio data, we reduce the sampling rates to ≤ 1 kHz. Subsampling can be implemented directly and easily at the hardware level; i.e., instead of post-processing fast-sampled audio data (e.g., 44 kHz), the sensor is directly sampled at a reduced rate. This approach saves power needed to sample, move/store in memory, and featurize the data. Our approach was partially inspired by the always-on "Measure Sounds" (loudness) feature found on recent Apple Watch models. This software-based sensor relies on the microphone, but presumably senses at a very low rate so as to have minimal impact on battery life. At these lower rates, human speech is also unintelligible, thus offering a more privacy-sensitive approach.
We show in our evaluation that motion and sound signals are complementary and provide wide coverage of numerous activities of daily living. A similar approach (albeit without subsampled audio) is reportedly used in Apple Watch’s handwashing recognition implementation, but there is no official documentation of the approach and its implementation. SAMoSA provides a generic, open-source approach that extends to 25 additional activities. Overall, this paper makes the following contributions:
- A practical activity recognition system that uses 50 Hz IMU along with audio sampled at ≤ 1 kHz, and yet still achieves performance comparable to models using more power-hungry and privacy-invasive 16 kHz audio data.
- A comprehensive suite of experiments, quantifying the efficacy of our system across 8 audio sampling rates, 4 contexts, 60 environments, and 26 activity classes. We also present a power consumption and a speech intelligibility study for different audio sampling rates.
- A new smartwatch sensor dataset with synchronized motion and sound data. We further showcase how our multimodal model resolves ambiguity among activities that are confused by a single modality alone.
- Open-sourced data, processing pipeline, and trained models to facilitate replication and further exploration and deployment in the field.
Citation:
Vimal Mollyn, Karan Ahuja, Dhruv Verma, Chris Harrison, and Mayank Goel. 2022. SAMoSA: Sensing Activities with Motion and Subsampled Audio. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 6, 3, Article 132 (September 2022), 19 pages. https://doi.org/10.1145/3550284